This is a revised post of an original article that I first published in December. Even though I thought that I was very meticulous in my research, something was pointed out to me that I was totally unaware of – Unicode character expansions. So apologies to the community with regard the first article that I published as some of the original content could have been misleading. Here is a new revised article that explains character expansions and how it can affect the comparison of data with these two collations.
Introduction
I was recently asked this question and at the time I answered off the top of my head that there is no functional difference between the two collations in terms of how the data is sorted, but you still shouldn’t intermix them freely within your database. Being fairly methodical though, afterwards I spent a little bit of time ensuring that what I had said was correct, but when I researched the subject matter a little further, I was very surprised at what I found and as such decided to write this article to share some of those findings with you. Collations are one area that some new SQL techies get tripped up on early on. I most certainly did many years ago when I first started to use SQL server and saw the infamous "cannot resolve the collation conflict between xx and xx" error far too many times!
You can download the SQL script for the examples in this blog here.
What is a collation?
Some quick background first though. A collation itself specifies the rules for how strings of character data are sorted and compared. The rules for sorting data vary depending on the language and locale. For example if you was to use a Lithuanian collation, the letter "Y" would appear between "I" and "J" if sorted. And if using the traditional Spanish collation "ch" would be sorted at the end of a list of words beginning with "c". To demonstrate:
--Create a table using collation Latin1_General_CI_AS and add some data to it
CREATE TABLE MyTable1
(
ID INT IDENTITY(1, 1),
Comments VARCHAR(100) COLLATE Latin1_General_CI_AS
)
INSERT INTO MyTable1 (Comments) VALUES ('Chiapas')
INSERT INTO MyTable1 (Comments) VALUES ('Colima')
--Create a second table using collation Traditional_Spanish_CI_AS and add some data to it
CREATE TABLE MyTable2
(
ID INT IDENTITY(1, 1),
Comments VARCHAR(100) COLLATE Traditional_Spanish_CI_AS
)
INSERT INTO MyTable2 (Comments) VALUES ('Chiapas')
INSERT INTO MyTable2 (Comments) VALUES ('Colima')
SELECT * FROM MyTable1 ORDER BY Comments
SELECT * FROM MyTable2 ORDER BY Comments
GO
And the results from that script
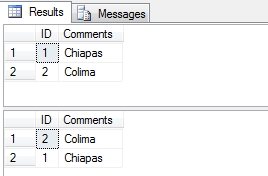
Just by using a different collation on the column, we get completely different results when the data is ordered by that column, so getting the collation correct is fundamental if you require your data to sorted and compared correctly. You can query the available collations by using the built in table function fn_helpcollations() e.g
SELECT * FROM fn_helpcollations()
GO
SQL server collations have evolved greatly since version 6.5 and the subject matter itself is far too vast for one blog. So if you are interested in researching it further, this SQL 2005 white paper is a very good starting point for those wishing to dig much deeper into the technology.
SQL_Latin1_General_CP1_CI_AS vs Latin1_General_CI_AS
I’m going to use the SQL function COLLATIONPROPERTY to find out a little bit more about how the collation is defined within SQL server. This function takes in a two parameters, the first is the collation name and the second is the property you require from the collation.
SELECT 'SQL_Latin1_General_CP1_CI_AS' AS 'Collation',
COLLATIONPROPERTY('SQL_Latin1_General_CP1_CI_AS', 'CodePage') AS 'CodePage',
COLLATIONPROPERTY('SQL_Latin1_General_CP1_CI_AS', 'LCID') AS 'LCID',
COLLATIONPROPERTY('SQL_Latin1_General_CP1_CI_AS', 'ComparisonStyle') AS 'ComparisonStyle',
COLLATIONPROPERTY('SQL_Latin1_General_CP1_CI_AS', 'Version') AS 'Version'
UNION ALL
SELECT 'Latin1_General_CI_AS' AS 'Collation',
COLLATIONPROPERTY('Latin1_General_CI_AS', 'CodePage') AS 'CodePage',
COLLATIONPROPERTY('Latin1_General_CI_AS', 'LCID') AS 'LCID',
COLLATIONPROPERTY('Latin1_General_CI_AS', 'ComparisonStyle') AS 'ComparisonStyle',
COLLATIONPROPERTY('Latin1_General_CI_AS', 'Version') AS 'Version'
GO
and the results

We can see that the code page, language code identifier and comparison style are all identical. The "Version" column denotes which SQL version the collation was introduced with. This query would lead you to believe that the two collations are the same with regard to the language/locale and you would expect to get identical results when using either collation. But just because they appear to be the same, you shouldn’t freely mix them up within your database or instance. For example, if we run the following SQL batch.
--Clean up previous query
IF EXISTS(SELECT 1 FROM sys.tables WHERE Name = 'MyTable1')
DROP TABLE MyTable1
IF EXISTS(SELECT 1 FROM sys.tables WHERE Name = 'MyTable2')
DROP TABLE MyTable2
--Create a table using collation Latin1_General_CI_AS and add some data to it
CREATE TABLE MyTable1
(
ID INT IDENTITY(1, 1),
Comments VARCHAR(100) COLLATE Latin1_General_CI_AS
)
INSERT INTO MyTable1 (Comments) VALUES ('Chiapas')
INSERT INTO MyTable1 (Comments) VALUES ('Colima')
--Create a second table using collation SQL_Latin1_General_CP1_CI_AS and add some data to it
CREATE TABLE MyTable2
(
ID INT IDENTITY(1, 1),
Comments VARCHAR(100) COLLATE SQL_Latin1_General_CP1_CI_AS
)
INSERT INTO MyTable2 (Comments) VALUES ('Chiapas')
INSERT INTO MyTable2 (Comments) VALUES ('Colima')
--Join both tables on a column with differing collations
SELECT * FROM MyTable1 M1
INNER JOIN MyTable2 M2 ON M1.Comments = M2.Comments
GO
We get the dreaded:
Msg 468, Level 16, State 9, Line 14
Cannot resolve the collation conflict between "SQL_Latin1_General_CP1_CI_AS" and "Latin1_General_CI_AS" in the equal to operation.
Which is caused by the join condition trying to compare string values where the collation is different on each side of the operator. Because each side of the equals to operator has an implicitly defined collation, SQL cannot resolve the collation conflict and has to raise the error. Incidentally, if one side of the equal’s operator had an explicitly defined collation, then this error would not have occurred. See collation precedence later on in this blog.
The difference between the two collations
Ok, we know that at face value, the two collations seem to functionally work in the same way and also we know what we cannot directly compare values having different implicitly defined collations which is understandable, but what else under the hood is different? First of all, I’m going to create an index on the Comments column of both of the tables in the example.
CREATE INDEX IX_Comments ON MyTable1(Comments)
CREATE INDEX IX_Comments ON MyTable2(Comments)
Now I’m going to run these very simple queries against the two tables and look at the execution plan
DBCC FREEPROCCACHE
GO
SELECT Comments FROM MyTable1 WHERE Comments = 'Colima'
GO
DBCC FREEPROCCACHE
GO
SELECT Comments FROM MyTable2 WHERE Comments = 'Colima'
GO
The execution plan unsurprisingly looks a bit like this, a single index seek in each of the two queries.
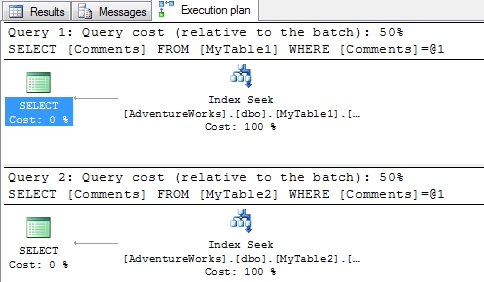
Let’s check the index seeks on the two queries a bit more closely though
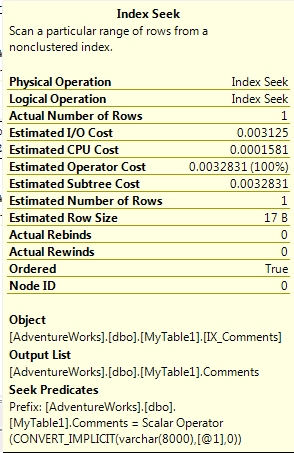
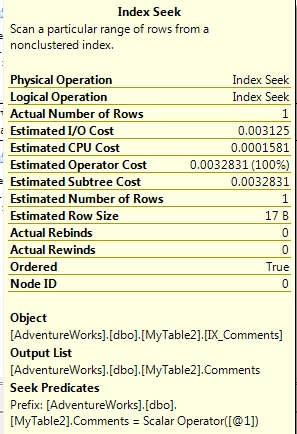
That is interesting; on MyTable1 the table with a varchar column using collation Latin1_General_CI_AS collation SQL is doing an implicit conversion during the lookup. Where has this implicit conversion come from? Well, it is caused by the collation of the database that I am running the query against. In this case I was running the queries against the AdventureWorks database which has a collation of SQL_Latin1_General_CP1_CI_AS. When an object is declared in a user-defined function, stored procedure, or trigger, it is assigned the default collation of the database in which the function, stored procedure, or trigger is created. If the object is declared in a batch, it is assigned the default collation of the current database for the connection. The database collation was set to SQL_Latin1_General_CP1_CI_AS and as a result, the collation of the string was also set to SQL_Latin1_General_CP1_CI_AS. You’ll be right at this point to be thinking why the comparison of two values with different collations didn’t cause the collation conflict error as above? Well this is all down to something called collation precedence. The implicit collation against the column takes precedence over the string value and SQL was able to do this CONVERT_IMPLICIT of the string to match the collation of the column i.e. Latin1_General_CI_AS.The other index seek on MyTable2 (varchar column using collation SQL_Latin1_General_CP1_CI_AS) is exactly what you would expect
Now, I’m going to run the same query again, but this time I’m going to compare the varchar columns in the two tables with nvarchar values and check the execution plans again. I’m also going to force the collation to Latin1_General_CI_AS on the string for MyTable1 to ensure that it does not pick up the database collation and do an implicit conversion in the plan. (I’m sure there may be a better way of doing this by the way rather than a sub-query!)
DBCC FREEPROCCACHE
GO
SELECT Comments FROM MyTable1 WHERE Comments = (SELECT N'Colima' COLLATE Latin1_General_CI_AS)
GO
DBCC FREEPROCCACHE
GO
SELECT Comments FROM MyTable2 WHERE Comments = N'Colima'
GO
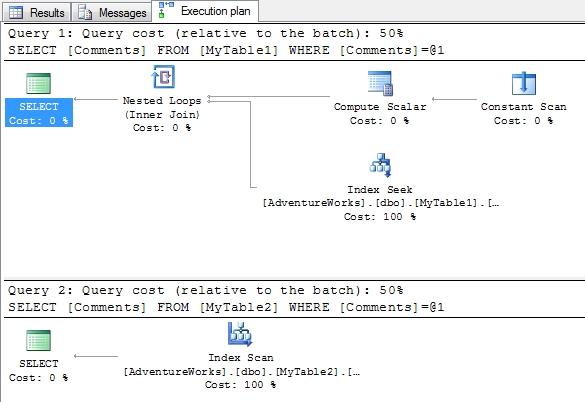
The plans are quite a bit different this time. Firstly, the first query has still managed to perform an index seek operation, but if you check the operator in more detail (below) it has performed a CONVERT_IMPLICIT on the column data and the seek predicate has changed to a range rather than an equals to. However, the second query on table 2 which has the SQL_Latin1_General_CP1_CI_AS collation can no longer perform an index seek. Instead it has performed an index scan which compared to the index seek could be quite expensive on large tables.
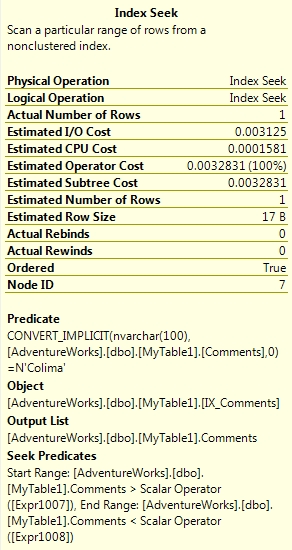
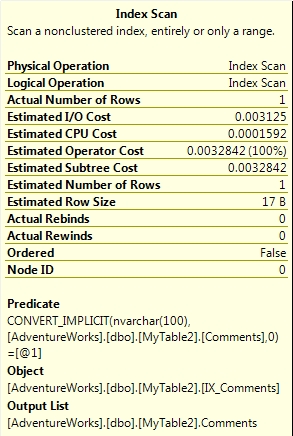
Why is this? The reason behind all of this is down to the actual differences between the two collations. The SQL_Latin1_General_CP1_CI_AS collation is a SQL collation and the rules around sorting data for unicode and non-unicode data are different. The Latin1_General_CI_AS collation is a Windows collation and the rules around sorting unicode and non-unicode data are the same. A Windows collation as per this example can still use an index if comparing unicode and non-unicode data albeit with a slight performance hit. A SQL collation cannot do this as shown above and comparing nvarchar data to varchar removes the ability to perform an index seek.
But, are there any other differences?…. Indeed there are
Character Expansions
There are some characters that are treated as an independent letter but can be expanded to a sequence of characters in certain collations. For example the latin letter æ can be expanded to the sequence "ae" in some collations. Similar, the ß can be expanded to "ss" and œ to "oe". To demonstrate this:
CREATE TABLE MyTable3
(
ID INT IDENTITY(1, 1),
Comments VARCHAR(100)
)
INSERT INTO MyTable3 (Comments) VALUES ('strasse')
INSERT INTO MyTable3 (Comments) VALUES ('straße')
SELECT * FROM MyTable3 WHERE Comments COLLATE Latin1_General_CI_AS = 'strasse'
SELECT * FROM MyTable3 WHERE Comments COLLATE Latin1_General_CI_AS = 'straße'
The query returns the following:
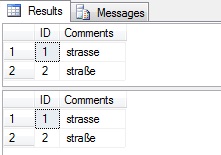
By using the windows Latin1_General_CI_AS collation, both queries have been able to return both records even though the string literal that is being compared only directly matches to one record. The collation has expanded the ß to ss and made them equivalent when comparing the data. This is line with unicode rules and even though the column is a varchar column, because we are using a windows collation, the same rules are being used for both unicode and non-unicode data. As an aside, this can give you some interesting problems if you are performing a LIKE type query, e.g. LIKE '%ß%' as this will find any value containing "ss" e.g. business.
Anyway, if we perform the same test again but using a SQL collation
SELECT * FROM MyTable3 WHERE Comments COLLATE SQL_Latin1_General_CP1_CI_AS = 'strasse'
SELECT * FROM MyTable3 WHERE Comments COLLATE SQL_Latin1_General_CP1_CI_AS = 'straße'
The following is returned:
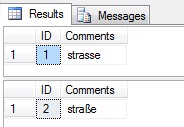
The SQL collation has compared the values as string literals and only returned the matching records without expanding the characters. Again, caused by the fact that its rules for comparing non-unicode data and unicode data are different and this character expansion doesn’t seem to exist within the non-unicode part of the SQL_Latin1_General_CP1_CI_AS collation. It must be noted that if the column type was nvarchar or the string variable being compared was of a nvarchar data type, then this problem wouldn’t occur under this collation as the SQL_Latin1_General_CP1_CI_AS collation would use its unicode rules for comparing the data which appear to be the same as the Latin1_General_CI_AS collation. And to show this is the case:
SELECT * FROM MyTable3 WHERE Comments COLLATE SQL_Latin1_General_CP1_CI_AS = N'strasse'
SELECT * FROM MyTable3 WHERE Comments COLLATE SQL_Latin1_General_CP1_CI_AS = N'straße'
Returns:
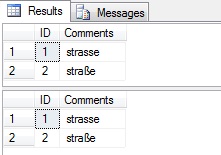
Conclusion
So to answer the question that I was asked regarding these two collations, I would have to say this: With varchar based data, there are small but significant differences with the sorting and comparison of data if you used the collation SQL_Latin1_General_CP1_CI_AS or if you used Latin1_General_CI_AS. Character expansion is one such difference and this difference is caused by the fact that the rules that both collations use for sorting/comparing are different. The rules for nvarchar data sorting/comparisons seem to be identical though from the tests that I have been able to do. Mixing the collations at column, database or instance level could impact on your performance quite heavily or cause collation conflict errors and mixing comparisons of varchar and nvarchar data as well can seriously impact on performance especially if you are using the older SQL collation. Keeping tabs on your collation settings across your SQL platform is very important.
There are various recommendations or rules of thumbs on what collation you should use for new instances as there are pros and cons for both but the general consensus tends to lean towards using the newer windows collations rather than the older SQL collations. But as always with SQL development, you need to evaluate all options and then test those options to see what works best within your infrastructure.
Enjoy!