It’s been a little while since I wrote a blog post on my favourite subject but this is from a thread on the SSC Xml forum that I was helping out on a couple of weeks ago. I’ve been a bit busy lately with a big project at work, revising/taking exam 70-461 and getting ready for the birth of my second child! But this thread seemed too good a subject for me to miss quickly get a post out showing how I might approach this particular problem.
Sometimes we are given a pretty poorly structured xml blob that does not follow best practice and we need to run some queries against it, or maybe shred into something more relational yet there is little scope to get the structure of the xml changed into something better before being given to us. In the perfect world we either wouldn’t accept such badly structured xml or work with the generators of said xml to make it better. But far too often this isn’t an option for whatever reason and we just have to get on with it. Don’t get me wrong, I’m not advocating working with bad xml structures! heck, I deal with a few of those myself from time to time and more often than not, it just isn’t cost effective for the business to go back to the source of the xml to get it re-worked.
Imagine this very simple, and poorly constructed piece of xml that contains an item number and its colour in the following node (download link for all examples at bottom):
DECLARE @xml XML SET @xml = ' <Data> <SomeElement>Item 1</SomeElement> <SomeElement>Red</SomeElement> <SomeElement>Item 2</SomeElement> <SomeElement>Green</SomeElement> <SomeElement>Item 3</SomeElement> <SomeElement>Blue</SomeElement> </Data>';
To shred all of the <SomeElement> nodes above to a single column table is very easy using the nodes() function:
SELECT t.c.value('(./text())[1]', 'varchar(10)') AS 'SomeElementValue'
FROM @xml.nodes('//SomeElement') AS T(c);
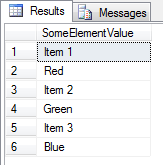
This is fine if all you want is a single column of all the values. But say that for each node in the xml, we need to extract the value of the following node or even the previous node. A bit like the LAG or LEAD windowing functions in SQL 2012. This is all possible to do with a little xquery creativity. One way of achieving this is by slightly remodelling the xml before using the nodes() function. For example:
WITH xCTE AS
(
SELECT @xml.query('
<Data>
{
for $x in (/Data/SomeElement)
return
<SomeElement>
<Value>{data($x)}</Value>
<PrevValue>{data(/Data/SomeElement[. << $x][last()])}</PrevValue>
<NextValue>{data(/Data/SomeElement[. >> $x][1])}</NextValue>
</SomeElement>
}
</Data>
') AS DocXml
)
SELECT t.c.value('(Value/text())[1]', 'varchar(10)') AS 'SomeElementValue'
, t.c.value('(PrevValue/text())[1]', 'varchar(10)') AS 'PreviousSomeElementValue'
, t.c.value('(NextValue/text())[1]', 'varchar(10)') AS 'NextSomeElementValue'
FROM xCTE
CROSS APPLY DocXml.nodes('/Data/SomeElement') AS T(c);
I’ve used a CTE in this instance but you could do it other ways. Essentially what the query is doing is transforming the xml into something which facilitates you to shred the previous, or next element values. The key to the query is the xml node order comparison operator of << or >>. What the xquery is doing is that it is using a flwor statement to get a sequence of <SomeElement> nodes and for each node, it returns a new <SomeElement> node that contains three child elements. The first child node <Value> contains the value of the current <SomeElement> node in the sequence. The second node <PrevValue> contains the value of the node that immediately precedes the current <SomeElement> node. It does this by retrieving the very last node (last() function) of a sequence of <SomeElement> nodes that precede (<< operator) the current node. Finally a third node <NextValue> which contains the value of the node that is immediately after the current node of the sequence. This is achieved by getting a sequence of <SomeElement> nodes that are after the existing node (>> operator) and returns the first one ([1] predicate) of that sequence. Now with this transformed version of xml in the CTE it is really easy to shred out the values that we need.
When executed the results look like this. The first column has the value of each node, and the next two columns contain the value of the node immediately preceding or succeeding it:
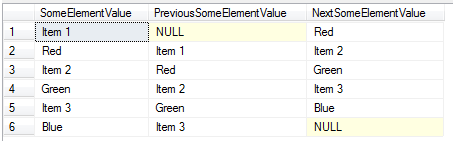
This is all well and good if you know what the name of the element is or if the name of the elements are all the same. What about if you don’t know what the names of the elements are going to be, or they vary and you still need to do the same as above? All you need to do is modify the previous query and use the * wildcard. Here is a revised xml with random element names and the query has been modified to select all child nodes (*) under the element.
SET @xml = '
<Data>
<SomeElement1>Item 1</SomeElement1>
<SomeElement2>Red</SomeElement2>
<SomeElement3>Item 2</SomeElement3>
<SomeElement4>Green</SomeElement4>
<SomeElement5>Item 3</SomeElement5>
<SomeElement6>Blue</SomeElement6>
</Data>';
WITH xCTE AS
(
SELECT @xml.query('
<Data>
{
for $x in (/Data/*)
return
<SomeElement>
<Value>{data($x)}</Value>
<PrevValue>{data(/Data/*[. << $x][last()])}</PrevValue>
<NextValue>{data(/Data/*[. >> $x][1])}</NextValue>
</SomeElement>
}
</Data>
') AS DocXml
)
SELECT t.c.value('(Value/text())[1]', 'varchar(10)') AS 'SomeElementValue'
, t.c.value('(PrevValue/text())[1]', 'varchar(10)') AS 'PreviousSomeElementValue'
, t.c.value('(NextValue/text())[1]', 'varchar(10)') AS 'NextSomeElementValue'
FROM xCTE
CROSS APPLY DocXml.nodes('/Data/SomeElement') AS T(c);
This returns exactly the same as above but this time you haven’t specified the name of the node as part of the flwor statement in the CTE:
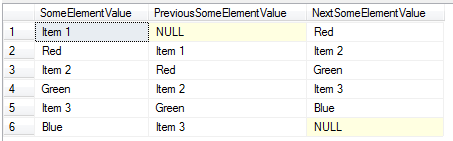
Enjoy!