I was going through some really old blogging ideas and I stumbled over this one and seeing as I love finding creative solutions in XQuery, I’m not sure why I hadn’t got this down into a blog post earlier!
Imagine the following contrived xml snippet which is essentially just a set of key/value pairs. At the moment the key names are not unique and have duplicates and in this scenario we need to make the key names unique whilst keeping the key value the same.
declare @xml xml =' <UnitInformation> <section name="Unit Information"> <setting name="AccountId" value="P5" /> <setting name="Complete" value="1" /> <setting name="AccountId" value="P7" /> <setting name="AccountId" value="P12" /> <setting name="Complete" value="1" /> <setting name="Complete" value="1" /> </section> </UnitInformation>'
One solution that I came up with used a FLWOR expression to loop over the nodes and generate a new XML structure. The basic concept is that the FLWOR loop would navigate down through each <setting> node and test to see if there are any other <setting> nodes with the same @name value preceding it in the document. If there is then it would append a sequential number to the end of the key name to make it unique within the document, if not then keep the existing name value.
The final solution looked like this:
SELECT @xml.query('
<UnitInformation>
<section name="Unit Information">
{
for $x in /UnitInformation/section/setting
return
if((count(/UnitInformation/section/setting[@name=$x/@name][. << $x])) > 0)
then
<setting name="{data(concat($x/@name, "_",
xs:string(count(/UnitInformation/section/setting[@name=$x/@name][. << $x]))))}"
value="{data($x/@value)}" />
else
$x
}
</section>
</UnitInformation>' )
It looks more complicated than it really is but let’s dissect it piece by piece. Firstly the FLWOR constructor

All this is doing is setting up a for each loop over a collection of xml nodes, namely <setting> and assigning each instance to local variable $x during the enumeration. During each loop it will return either the assigned variable, $x, or a new XML node depending on the outcome of the if condition:

This looks complicated at first, but lets focus on the IF condition and in particular the XPath expression that has been passed into the count() function. This expression is looking for all <setting> nodes where the @name attribute is identical to the @name attribute of the variable and also where the position of that xml node precedes the one in the variable in the document order (Remember that the variable is looping through each <setting> node as part of the for statement). The double less than test << is an XQuery order comparison test and is really useful in determining position of the XML nodes within an XQuery.
So this will generate a sequence of zero or more nodes that are passed into the count function. If the count returns zero then the test didn’t find any <setting> nodes with the same @name attribute as the one in the for each variable and it will simply return the $x variable which is the entire <setting> node plus its two attributes. But if the count returns a non-zero value then it did find at least one duplicate @name in a previous node and it will create a new <setting> node.
When constructing the new <setting> node, for the @name attribute value, it concatenates the original @name value with an underscore and then the number of nodes that precede it with the same @name value i.e. the exact same number it got back during the IF condition above. The @value attribute is simply extracting the original value from the variable $x.
Phew!..
When run, you’ll get a result like the below, note that duplicate key names are now made unique:
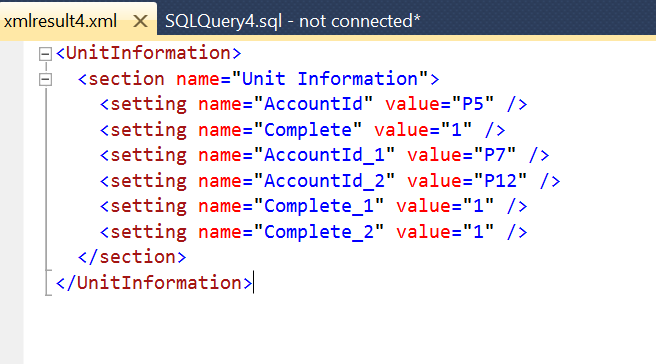
I think XQuery is one of the gems in SQL server, a bit like service broker. It is a bit hard at first to get into but once you do, you realise just how powerful it can be. Don’t get me wrong, XQuery is slow in SQL comparatively so you wouldn’t want to be passing millions of XML structures through XQuery expressions regularly but it can be a fantastic option for quick ad hoc XML manipulation in the database rather than shipping it out to an application service layer to do the transformations. I hope JSON goes the same way with a dedicated data type being added with its own set of methods in a future SQL version.
Enjoy!……
Follow me on twitter @sqlserverrocks
Subscribe to my blog RSS feed
Comment on this or any of my posts or contact me directly from http://www.olcot.co.uk