Have you ever had that moment where you have gone “Geez.. I wish I’d learnt this stuff ages ago” after realising just how much more productive you’d have been since!! That happened to me recently after taking literally a few minutes to learn more about the find/replace regular expression option in SSMS.. It has long been on my list of things to make more use off (alongside powershell!) and although I have used regular expressions on the odd occasion in .NET over the past couple of years, I never really picked up on them in SSMS. I spotted Jen McCown‘s recent blog post on the same subject and I thought, rights that it, I’m going to spend the time to learn this feature instead of string hacking the hard way in SSMS or Excel…. and it wasn’t long before I had an opportunity to do so the very same day..
We all must have at least once been given a list of maybe 10, 50, 100 or whatever number of key values via email, text file etc and needed to get a list of records from a table based on those key values. Because it is a one off job, how many times have we just pasted that list into SSMS and proceeded to quickly knock up construct a SELECT statement with an IN clause of the key values and then went through and put a comma at the end of each value in the list to make it well formed tsql… very monotonous and tedious for the minute or two that it takes… or worse still, have to make them string values by putting apostrophes at either end of each value AND comma separate them ready for the IN clause..
This was the very scenario I had [again] but this time I forced myself to use RegEx to comma separate the values and soon found out that this was ridiculously easy to do in SSMS… All I did was paste the list of values into an SSMS window, highlight them all, press Ctrl-H to bring up find/replace box. Then in the Find what box I typed ‘$’, which is the expression to find the end of a line and in the Replace with box, I typed ‘,’ then changed it to use ‘Regular Expressions’ and voila! a comma at the end of each value on each line. A 10 second process if that.. I trimmed off the last comma, wrapped them all with brackets and there was the IN part of my SELECT query. I’ve already lost count of how many times I’ve used this method since learning this..
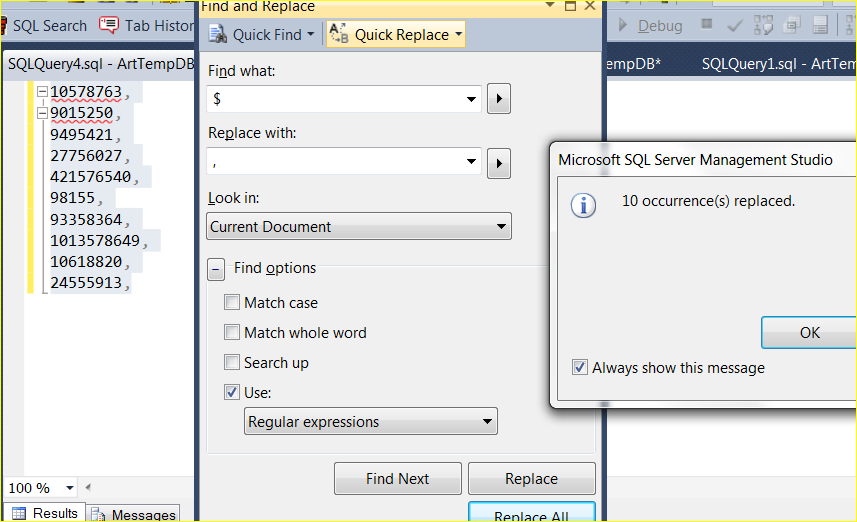
Similar to appending data at the end of a line of text, if I wanted to prepend data at the start of the line then that is just as easy. To find the start of the line via RegEx, you can use ‘^’ and you can instead prepend data to the start of each line.
Taking the previous example a step further, if I wanted to convert the list of key values to string values ready for me to use in a SELECT query, that is also pretty easy to do with the find expression of ^{.*}$ and the replace expression of '1',
What the find expression is doing is finding the start of the line (^), then any number of characters (.*) that follow and then the end of the line ($). The curly braces is tagging the any number of characters it founds between the start and the end of the line so that we can reference it in the replace expression. The replace expression references the tagged data by the (1) expression.
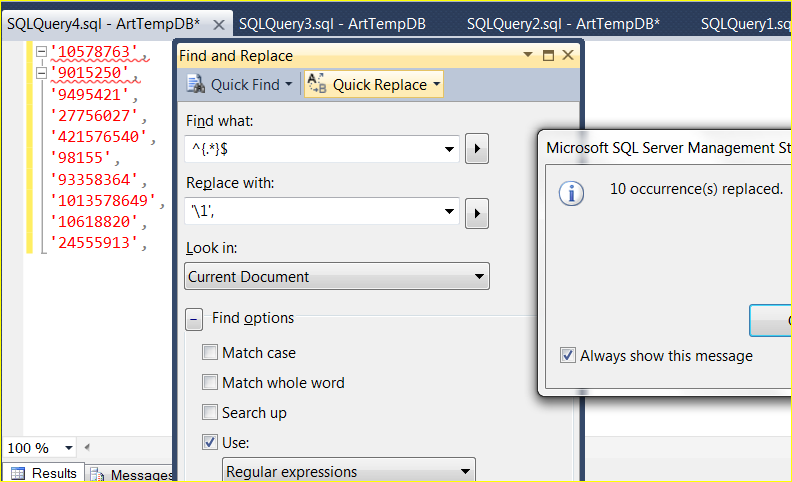
If you have a list of 100’s of values then this allows you get them in a way ready for your query in a matter of seconds.
Phil Factor has a blog post with a whole of list of scenarios and expressions to remodel the scripts/statements that you have and well worth flicking through just to get a feel for the variety of use cases. It also goes into great detail the RegEx expressions which I’m not going to regurgitate here.
Once you get the hang of RegEx, you can get really creative with the expressions and find/replace in ways you’d never have thought of before. For example, imagine you have a bunch of 100’s or 1000’s of INSERT statements e.g:
INSERT INTO dbo.Customers (CustomerId, CustomerName, CustomerAddress, CustomerComments) VALUES (1, 'SomeCustomer1', 'SomeAddress1', 'Comments') INSERT INTO dbo.Customers (CustomerId, CustomerName, CustomerAddress, CustomerComments) VALUES (2, 'SomeCustomer2', 'SomeAddress22', 'Comments') INSERT INTO dbo.Customers (CustomerId, CustomerName, CustomerAddress, CustomerComments) VALUES (3, 'SomeCustomer3', 'SomeAddress333', 'Comments')
And for whatever reason, you want to remove column 3 (CustomerAddress) completely from all of the INSERT statements.. To achieve this by hand, you’d need to go through and first remove the column reference (easy enough using find/replace), but you also need to remove the value as well.. Not so easy using traditional replace. But it is with a regular expression using a find expression similar to {(([:a']+, )^2}[:a']*, And the replace expression of 1
Try it on the example and see.. (see Phil Factor’s post or the Technet article for a more detailed explanation of each element of the expression) but basically it is looking for the first three columns based on the comma after the opening bracket but keeping the first two columns tagged (the curly braces). It then replaces what it finds with the tagged data.
What about taking the example above and converting the INSERT statements to an UPDATE statement updating the CustomerName based on the CustomerId in one swoop. You can by building up and using a find expression along the lines of INSERT INTO .*$n.*({[:a]+}, {[:a']+}.*) which finds each INSERT statement tagging the relevant parts that we want to use during the replace operation and then replace that data with the expression UPDATE dbo.Customers SET CustomerName = 2 WHERE CustomerId = 1
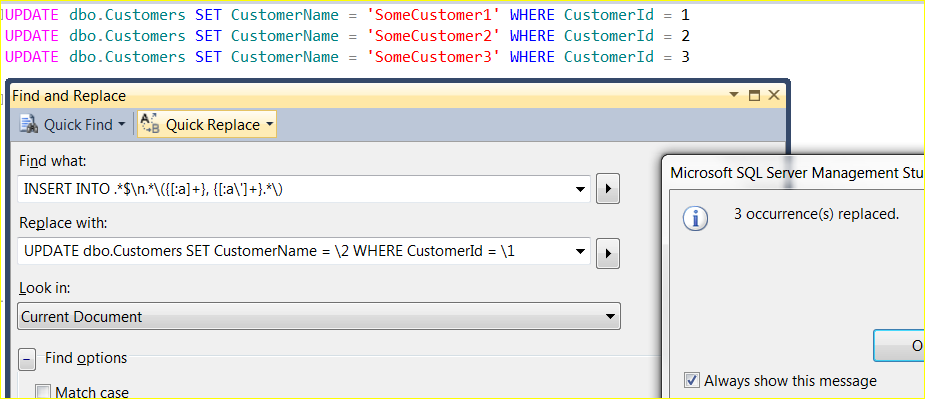
Pretty simple stuff, but awesome nonetheless and if you haven’t learnt regular expressions yet (and you frequently do what I used to do in SSMS!), then seriously, push yourself to try to use them the next time you get an opportunity to do so.. Only shame is that Microsoft use their own version of RegEx which isn’t 100% in line with that found in .NET and other languages.
Enjoy!